Metode ilmiah adalah suatu metode atau cara untuk memecahkan suatu masalah dengan langkah-langkah tertentu, sistematis, logis dan empiris. Hal ini mengandung arti bahwa langkah-langkah yang dilakukan harus sesuai urutannya, tidak boleh dibolak balik.

(1) Ilmuwan melakukan pengamatan dan membuat hipotesis dalam usahanya untuk menjelaskan fenomena alam;
(2) prediksi yang dibuat berdasarkan hipotesis diuji dengan melakukan percobaan atau eksperimen;
(3) hipotesis yang telah lolos uji berkali-kali dapat menjadi teori ilmiah.
Baca Juga : Gambar Dataran Rendah
Metode ilmiah yang harus dilakukan oleh para ilmuwan untuk menemukan teori adalah pengulangan dari langkah-langkah tersebut di bawah ini:
-
Mengadakan pengamatan, dari pengamatan kemudian dibuat atau dirumuskan masalah (melakukan karakterisasi setelah mealkukan pengamatan dan pengukuran)
-
Membuat hipotesis (menyusun dugaan yang bersifat sementara atas hasil pengamatan dan pengukuran) dari masalah tersebut
-
Prediksi (deduksi logis dari hipotesis)
-
Melakukan percobaan atau eksperimen (pengujian atas semua hal yang terdapat pada point 1-3)
-
Menarik kesimpulan
Langkah-Langkah Metode Ilmiah
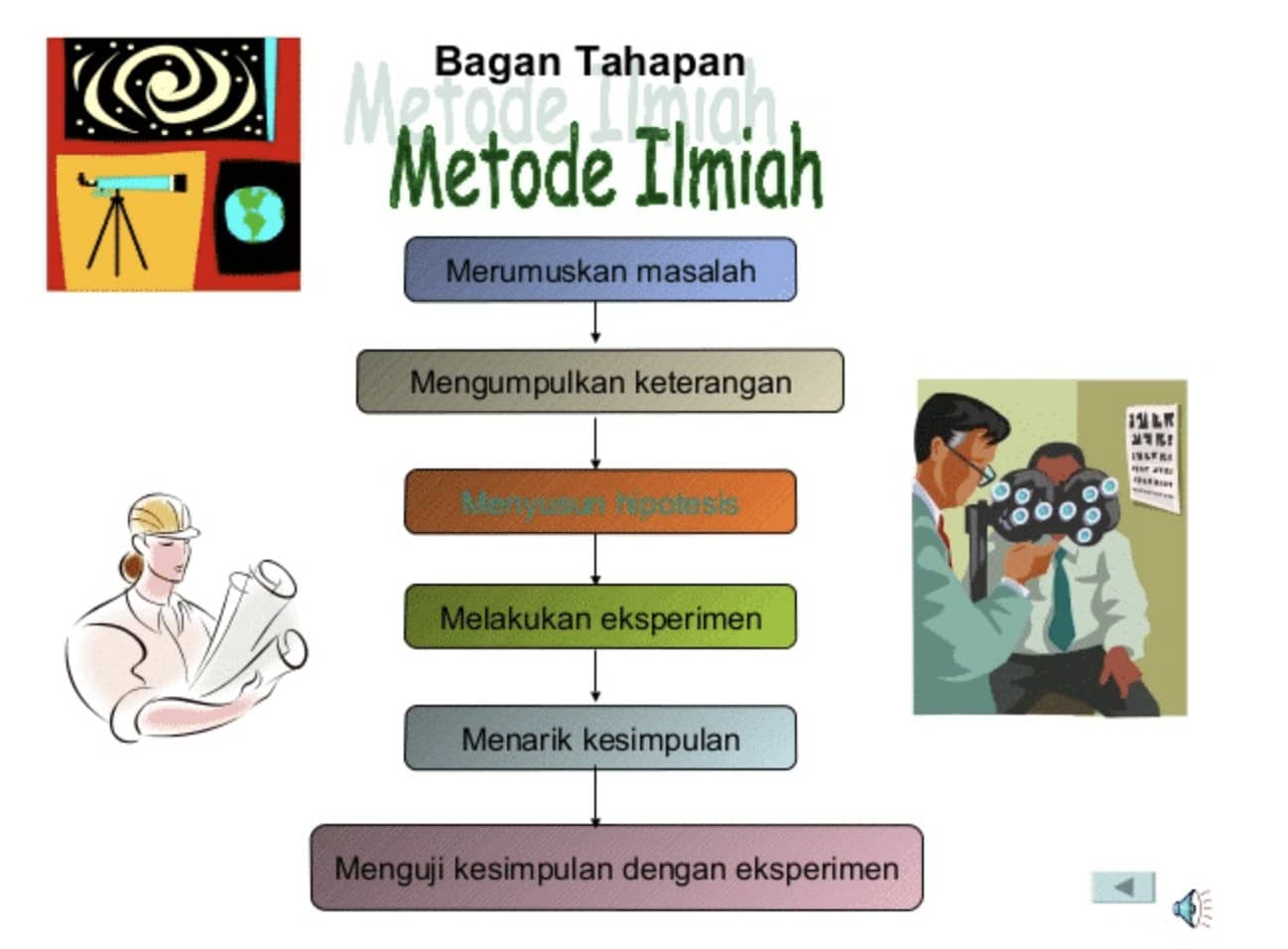
Merumuskan masalah
Bagaimana membuat rumusan masalah dari hasil pengamatan ?
Misalnya anda diminta mengamati tumbuhnya bayam di sekitar kandang dengan tumbuhnya bayam di bawah pohon mangga. Dalam pengamatan ini Anda diminta mengamati kondisi fisik tanah dan memperkirakan kandungan zat hara tanah serta suhu di tempat tumbuhnya bayam. Kemudian Anda diminta menulis satu rumusan penelitian.
Baca Juga : Sistem Koloid
Untuk membuat rumusan masalah, para ilmuwan mengidentifikasi sifat-sifat utama yang relevan yang dimiliki oleh subyek yang diteliti. Dalam proses ini dapat melibatkan proses pengamatan yang seringkali memerlukan pengukuran dan atau analisa yang cermat. Proses pengukuran dan analisa sering memerlukan alat ilmiah khusus seperti termometer, AAS, mikroskop, spektrometer dan lain-lainnya.
Hasil pengukuran bisa ditabulasikan dalam tabel, digambarkan dalam bentuk grafik atau dipetakan dan diproses dengan perhitungan statistik seperti korelasi dan regresi atau secara deskriptif. Dengan demikian melalui pengamatan dan pengukuran maupun anlisa dapat merumuskan masalah penelitian.
Untuk membuat hipotesis anda diminta mencermati pernyataan yang menyatakan bahwa kesuburan tanah dapat diidentifikasi dari kondisi fisik dan kandungan zat haranya. Tanah yang gembur dan kandungan zat hara tinggi dapat meningkatkan pertumbuhan tanaman. Berdasarkan pernyataan tersebut di atas dan rumusan masalah pada point 1, buatlah hipotesis penelitiannya.
Hipotesis merupakan pernyataan sementara yang perlu dibuktikan kebenarannya. Para ahli menyatakan bahwa hipotesis adalah dugaan terhadap hubungan antara dua variabel atau lebih. Sehingga hipotesis sering dinyatakan sebagai jawaban sementara atau dugaan sementara yang harus diuji kebenarannya.
Hipotesis penelitian adalah hipotesis kerja, yaitu hipotesis yang dirumuskan untuk menjawab permasalahan berdasarkan teori- teori yang relevan dengan rumusan masalah penelitian dan belum berdasarkan fakta atau dukungan data yang nyata dari hasil kerja di lapangan. Dengan demikian melalui prediksi berdasarkan teori-teori yang relevan dengan permasalahan dapat dirumuskan hipotesis.
Baca Juga : Adaptasi Makhluk Hidup
Eksperimen
Bagaimana melakukan eksperimen ?
Berdasarkan rumusan masalah dan hipotesis dibuatlah rancangan penelitian atau eksperimen. Untuk itu perlu diidentifikasi terlebih dahulu variabel bebas, variabel terikat dan variabel kontrol. Berdasarkan ketiga variabel tersebut dibuatlah rancangan eksperimen dan selanjutnya dilakukan percobaan atau eksperimennya.
Jika hasil eksperimen tidak sesuai atau bertentangan dengan hipotesis maka hipotesis yang diuji tidak benar atau tidak lengkap sehingga perlu dianalisis mengapa hasilnya demikian. Dengan demikian akan bisa ditentukan apakah perlu ada perbaikan atau bahkan ditinggalkan. Jika hasil eksperimen sesuai dengan hipotesis, maka hipotesis tersebut benar namun masih perlu diuji lebih lanjut. Hasil eksperimen tidak bisa membenarkan suatu hipotesis melainkan hanya bisa meningkatkan probabilitas kebenaran hipotesis tersebut.
Tetapi hasil eksperimen secara mutlak dapat menyalahkan suatu hipotesis bila hasil eksperimen bertentangan dengan hipotesis. Eksperimen dapat dilakukan di dalam laboratorium maupun di luar laboratorium. Yang perlu diperhatikan adalah pencatatan yang detail dari suatu eksperimen, hal ini sangat membantu dalam pelaporan hasil eksperimen dan memberikan bukti efektivitas dan keutuhan prosedur yang dilakukan.
Merumuskan Kesimpulan
Bila langkah merumuskan masalah, prediksi dari hipotesis, rancangan eksperimen dan eksperimen dilakukan secara sistematis maka akan dapat dibuat kesimpulan dari hipotesis yang diuji yaitu pupuk dapat mempengaruhi (meningkatkan ) pertumbuhan tanaman.
Baca Juga : Hewan Adalah
Kesimpulan ini diperoleh dengan melakukan analisis data dan pembahasan berdasarkan landasan teoritis dan empiris yang dikembangkan berdasarkan data hasil eksperimen. Perlu diperhatikan bahwa seseorang yang melakukan proses metode ilmiah perlu didasari sikap ilmiah dan sikap ilmiah ini semestinya dipunyai oleh setiap peneliti dan para ilmuwan.
Sikap ilmiah yang dimaksud adalah jujur (menerima kenyataan hasil penelitian apa adanya tanpa harus melakukan modifikasi dan tidak mengada-ada), obyektif ( sesuai dengan fakta yang ada), teliti ( tidak ceroboh dan tidak melakukan kesalahan), terbuka (mau menerima pendapat yang benar dariorang lain) dan rasa ingin tahu yang tinggi.
Keterampilan Proses Sains
- Menerapkan keterampilan proses Sains dalam mempelajari Biologi
Keterampilan proses merupakan cara memandang siswa sebagai manusia seutuhnya, yang mana siswa juga memiliki potensi, kreasi, keingintahuan, dan perasaan. Cara memandang ini diekspresikan dalam kegiatan pembelajaran yang memungkinkan siswa diberi kesempatan untuk mengembangkan kemampuan pengetahuan, sikap dan nilai serta keterampilan-keterampilan ilmiah. Keterampilan ilmiah atau keterampilan sains merupakan seperangkat keterampilan yang digunakan para ilmuwan dalam melakukan penelitian ilmiah.
Keterampilan proses sains ini perlu dilatihkan kepada siswa dengan alasan:
(1) dalam praktiknya, sains tidak bisa dipisahkan dari metode ilmiah atau metode penyelidikan dan mengetahui sains tidak hanya sekedar mengetahui materi tentang sains tetapi juga bagaimana cara untuk mendapatkan materi sains tersebut;
(2) keterampilan proses sains merupakan merupakan keterampilan belajar sepanjang hayat yang dapat digunakan tidak hanya untuk mempelajari ilmu tetapi juga dapat digunakan dalam kehidupan sehari-hari bahkan untuk bertahan hidup.
Baca Juga : Fenotip Adalah
Keterampilan proses melibatkan keterampilan kognitif, manual dan sosial. Keterampilan manual jelas terlibat dalam keterampilan proses karena keterlibatannya dalam penggunaan alat dan bahan, pengukuran dan perakitan alat. Keterampilan sosial jelas terlibat dalam hal mendiskusikan hasil pengamatan.
Dalam pembelajaran Biologi keterampilan proses perlu dikembangkan melalui pengalaman langsung sebagai pengalaman belajar dan disadari ketika kegiatannya sedang berlangsung. Hasil penelitian menunjukkan bahwa melalui pengalaman langsung seseorang dapat lebih menghayati proses atau kegiatan yang dilakukan tetapi apabila hanya sekedar melaksanakan tanpa menyadari yang sedang dikerjakan maka hasilnya kurang bermakna dan memerlukan waktu yang lama untuk menguasainya.
Dalam pembelajaran Biologi keseimbangan antara perolehan produk (konsep/pengetahuan) dan kemampuan yang berkembang selama proses belajar melalui keterampilan proses merupakan hal yang harus dipertimbangkan guru Biologi.
Berdasarkan berbagai pendapat tentang komponen keterampilan proses, komponen keterampilan yang dapat dikembangkan melalui pembelajaran Biologi bersifat relatif. Oleh karena itu, di bawah ini disajikan jenis keterampilan proses sains beserta indikatornya yang dapat diberikan dalam bahan ajar ini tidak mutlak. Secara prinsip komponen keterampilan proses yang dapat diberikan kepada siswa adalah sebagai barikut.
Baca Juga : Jenis Flora Di Indonesia
-
Mengamati /observasi dan Menafsirkan pengamatan
- Mengamati merupakan keterampilan proses yang menjadi dasar dari semua keterampilan. Dalam hal ini, mengamati adalah kemampuan menggunakan seluruh indera yang dimiliki oleh semua siswa dan mengumpulkan /menggunakan fakta yang relevan
- Menafsirkan pengamatan merupakan keterampilan mencatat hasil pengamatan, memisah-misahkan, mengklasifikasikan, menghubung-hubungkan sehingga diperoleh suatu pola
- Memprediksi
Penggunaan pola yang telah ditemukan pada saat melakukan pengamatan, dapat digunakan untuk mengemukakan kemungkinan-kemungkinan yang akan terjadi pada fenomena yang serupa. Jadi, proses melakukan prediksi ini merupakan sutau proses penalaran yang logis berdasarkan hasil pengamatan.
- Menggunakan peralatan dan Mengukur
Keterampilan ini merupakan kemampuan dalam memilih alat atau bahan yang sesuai serta kemampuan melakukan pengukuran suatu besaran dengan akurat. Jika hal ini dilakukan berulang-ulang, maka siswa akan mampu memperkirakan kesalahan yang dilakukan kemudian mengoreksinya.
- Mengajukan pertanyaan
Terbiasa mengajukan pertanyaan, secara tidak langsung dapat mengungkapkan seberapa jauh kemampuan kognisinya digunakan. Jenis dan substansi pertanyaan menunjukkan tingkat berpikirnya. Keterampilan ini akan berkembang jika guru sering memberikan kesempatan kepada siswa untuk berdiskusi.
- Merumuskan hipotesis
Keterampilan merumuskan hipotesis menekankan pada kemampuan menyatakan dan menentukan pola yang diperoleh sekaligus menyatakan kemungkinan akibat-akibat dari pernyataan yang dibuatnya.
- Merencanakan penyelidikan/percobaan
Keterampilan ini merupakan kemampuan siswa dalam merencanakan suatu percobaan untuk membuktikan atau menemukan suatu konsep. Kemampuan menentukan alat dan bahan yang digunakan, menentukan variabel-variabel, menentukan desain percobaan, menentukan langkah kerja serta bagaimana mengolah data merupakan kemampuan yang dapat dikembangkan melalui keterampilan ini.
- Menginterpretasikan
Keterampilan ini merupakan kemampuan siswa untuk menyimpulkan kecenderungan informasi yang diperoleh, membuat kesimpulan tentatif atupun membuat generalisasi.
- Berkomunikasi
Keterampilan ini merupakan kemampuan untuk menguraikan dengan jelas dan cermat apa yang telah dilakukan. Menyusunnya dalam berbagai sarana komunikasi (di depan kelas, diskusi, seminar, dsb.), menggambarkan hasilnya melalui gambar, skema, grafik adalah kemampuan yang dapat dikembangkan pada diri siswa.
- Mengelompokkan / Interpretasi
Keterampilan ini merupakan kemampuan untuk mencatat setiap pengamatan yang terpisah, mencari perbedaan dan persamaan, mencari dasar pengelompokan atau penggolongan dan menghubungkan hsil-hasil pengamatan.
- Menerapkan konsep
Keterampilan ini merupakan kemampuan untuk menggunakan konsep yang telah dipelajari pada situasi baru dan menggunakan konsep pada pengalaman baru untuk menjelaskan apa yang terjadi.
Baca Juga : Sistem Saraf Pada Manusia
Contoh Aplikasi Pendekatan Keterampilan Proses Untuk Meminta Siswa Melaksanakan Kegiatan :
-
Coba amati percobaanmu, catat perubahan-perubahan yang terjadi pada tanaman tersebut selama 1 minggu! (Keterampilan mengamati)
-
Pada saat melakukan kegiatan nomor (1), menurutmu apa yang akan terjadi pada pertumbuhan tanaman dalam pot/polybag? (Keterampilan menyusun hipotesis)
-
Jika tanaman tersebut dibiarkan pada posisinya selama 4 minggu, maka apa yang akan terjadi pada tanaman tersebut? (Keterampilan memprediksi)
Bagaimana pertumbuhan tanaman tersebut, jika setelah 2 minggu pot/polybag diubah posisinya menjadi berdiri? (Keterampilan memprediksi)
-
Kesimpulan apa yang dapat kamu peroleh melalui kegiatan seperti yang kamu lakukan (Keterampilan membuat kesimpulan)
-
Buatlah laporan singkat tentang hasil pengamatanmu (Keterampilan komunikasi)
Jadi melalui satu kegiatan, guru dapat mengembangkan beberapa keterampilan proses sekaligus. Sebagai konsekuensinya, dalam proses pembelajaran Biologi yang dikemas dengan pendekatan ini paling tidak membawa dampak pada:
- Pelaksanaan pembelajaran membutuhkan waktu yang cukup
- Kekhawatiran tidak dapat menuntaskan seluruh materi, jika selalu menggunakan pendekatan ini pada saat
- Guru harus memiliki waktu luang yang cukup untuk mempersiapkan
Demikianlah pembahasan mengenai Metode ilmiah Biologi -Pengertian, Langkah, Karakteristik, Contoh semoga dengan adanya ulasan tersebut dapat menambah wawasan dan pengetahuan anda semua, terima kasih banyak atas kunjungannya. 🙂 🙂 🙂